本帖最后由 silencedonkey 于 2024-12-14 01:45 编辑
前排提示:本教程发布时间较早,AI模型不断推陈出新,现在推荐上手使用更为强大的indigoXL与NoobAIXL系列模型,最新的AI绘图效果可以看楼主发布的新帖哦!教程除模型推荐外其他部分变化不大,仍然可以参考,若有问题可以私信楼主解决~
大家好,这里是沉默小驴,练习时长半年的AI毛茸茸兽人练习生。祝论坛里的大家十周年庆快乐 ,这也是我第一次赶上周年庆(前几年一直潜水来着),希望论坛和谐的氛围能够长长久久!(和谐区等得好辛苦 ,这也是我第一次赶上周年庆(前几年一直潜水来着),希望论坛和谐的氛围能够长长久久!(和谐区等得好辛苦 )在这个特殊的时间,当然也要和大家分享毛茸茸的快乐! )在这个特殊的时间,当然也要和大家分享毛茸茸的快乐!
拿AI来生成设定和头像实在是非常方便,楼主也给自己搞了一个,就是外表坏坏内心单纯的小鬣狗啦。某兽居然说小图看起来很胖,那就放出一个高清版本的好了。来,给大家打个招呼~  (如果有问为什么名字叫小驴,设定却是鬣狗兽人的,请立刻绞杀谢谢!) (如果有问为什么名字叫小驴,设定却是鬣狗兽人的,请立刻绞杀谢谢!)
之前的每次主题基本都有人问出图的方法,所以就想干脆授人以渔,在周年庆出一期更加详细的AI毛茸茸教程。(下次再有人问就可以直接甩链接了 )楼主最开始玩AI绘图就是期待能够把脑海中的场景变成现实(特别是色色),过去给大家分享过各式各样的主题,也尝试过精确控制包含剧情的场景,现在感觉基本上能够操控AI达成自己的想法了(虽然一些复杂的构图还是完成不好)。这次把之前的经验都总结一下分享给大家,想要自己上手尝试的不要错过啦,毕竟自己的XP还是要把握在自己手中,希望各位早日实现毛茸茸自由! )楼主最开始玩AI绘图就是期待能够把脑海中的场景变成现实(特别是色色),过去给大家分享过各式各样的主题,也尝试过精确控制包含剧情的场景,现在感觉基本上能够操控AI达成自己的想法了(虽然一些复杂的构图还是完成不好)。这次把之前的经验都总结一下分享给大家,想要自己上手尝试的不要错过啦,毕竟自己的XP还是要把握在自己手中,希望各位早日实现毛茸茸自由!
前排提醒:本期仅为个人向经验总结,楼主也只是在空闲时间自己探索,难免会有各种疏漏。主要为刚接触AI绘画的新手提供快速上手的方法,如有错误和没提到的地方欢迎评论补充纠正,让楼主也提高一下姿势水平。(本教程虽然是furry向的,不过很多技巧应该是通用的,非srk也可以选择性参考~)
本期也附赠了一个示例主题,对教程不感兴趣的小伙伴可以拉到后面看图~ (不过既然楼主费力写出来了,大家也了解一下AI绘图流程嘛,对于只是品鉴也能有帮助 ) )

一、前期准备
1. 理论
想要快速上手AI绘画,首先可以先拿知识武装自己。如果对自己有信心也可以跳过,先上手尝试,等遇到瓶颈之后再来针对性学习,大佬的经验总比自己摸索来得快不是嘛 。 。
这里推荐经典教材《元素同典:确实不完全科学的魔导书》,虽然版本比较老了(安装什么的就不用看了),但其中的一些通用理论还是非常有帮助的。如果你对于AI绘画还停留在刚接触阶段(或者还在复制成品图的关键词),在这里可以学到咒语构造法、权重调节等实用技巧,老手也可以熟悉一下咒语的叠加、分步、融合等高级技巧。
这部教材的语言还是非常生动幽默的,有很多实例与理论结合,对新手的理解非常有帮助!(不用担心理解门槛,楼主也是新手时期学习的。)
2. 工具
对于AI绘图的工具,本帖仅介绍stable diffusion本地部署(其他的楼主也没怎么用过)。相比其他在线生成的网站来说,优势是自由度非常高,而且可以色色!(大家都是冲这个来的吧 ) )
整合包:为了方便使用,网上可以找到各种stable diffusion webui的整合包(比最开始方便很多啦)。这里推荐新手可以用b站秋葉aaaki大佬的整合包与启动器,可以说是十分傻瓜式了,使用、维护和更新都没有什么门槛(甚至出问题还能帮你debug)。安装后应该就包含所有需要的环境了,而且是独立的不会与已有的python环境冲突,实在是非常贴心啦~ (注:stable diffusion本地部署应该都是免费开源的,如有遇到收费项目请勿轻信!)
显卡:既然是利用自己的设备进行运算,肯定是对于显卡有一定要求啦,理论上越高配置玩起来就越流畅丝滑。(楼主可没有在推销显卡哦,请各位量力而为)这里还是放上之前帖子里使用过的显卡出图速度参考。不过实际体验下来,一般20系的显卡应该就可以流畅玩耍了,注意需要Nvidia独立显卡。(楼主自己使用的是8g显存的2060s,速度可以接受,也能跑分辨率拉满的2k*2k图。)配置稍低的坛友可以在分辨率和运行速度上做一些妥协,或是尝试利用云服务等手段(之前论坛里有人介绍过,楼主不熟悉就不做推荐啦)。
二、模型
选一个合适的模型非常重要!!如果模型本身质量与稳定度都很好的话,出图下限是很高的,不用做过多调教也能有很不错的效果。
stable diffusion的可用模型非常丰富,基本都是使用者自行训练上传的,大家可以在模型分享网站civitai按名称与类别搜索。(可以经常逛逛,每次都有新感觉 也能找到不少令人眼前一黑的模型,只有你想不到~)需要注意的是c站的R18模型要注册后才能搜到。另外别忘了区分大模型和LoRA等,不少模型还有配套的VAE用来烘焙画风,所有类型都是下载后放到文件目录里对应的位置。(大模型和VAE要在设置里选好,LoRA和hypernet等可以在写咒语的时候调用。)
由于本期是毛茸茸专题,楼主就介绍一下用过的furry模型特点,方便各位针对性地选择(需要哪个请自行c站下载)。模型对应的画风可以通过传送门到楼主之前的帖子里做一下参考(当然现在看自己早期的作品很多细节都不过关,属于是黑历史了)。
1.yiffy-e18:楼主最早接触的模型,擅长欧美写实厚涂画风。优势是可绘制场景比较全面,不过细节和稳定度都比较差,目前已不再推荐使用。(风格可参考第一期、第二期、第三期、第四期、第五期。)
2.kavkaMix:非常写实的风格,可以绘制蓬松细致的毛发,根据发布者描述,比较擅长黑暗幻想类风格。人物细节较高,场景细节一般,稳定度尚可。(风格可参考第九期、第十二期。)
3.crosskemono:日系二次元风格,擅长立绘风格构图与富有张力的姿势。人物细节一般,场景细节较高,稳定度尚可。需要注意该模型角色覆盖面广,偶尔有女性化和幼龄化趋势,可用关键词压制。(风格可参考第十期、第十一期、第十三期。)
4.yiffy-mix:算是升级版的yiffy模型,同样是擅长欧美写实厚涂画风,场景自由度高。人物与场景细节都很高,稳定度较好。(风格可参考第十四期。)
5. Indigo Furry mix:比较推荐的模型,包含几个不同风格,日系二次元与欧美写实都有,也可以介于两者之间(楼主只尝试了anime和hybrid),训练集以雄性兽人为主。人物与场景细节尚可,稳定度较好,偏写实风格的模型细节会更好一点。(风格可参考这个帖子里的图和第十五期之后的主题。)
此外楼主尝试过模型融合(风格可参考第六期、第七期、第八期),一般是用来弥补当前模型在某方面的不足,建议足够熟悉模型的特点之后再进行尝试。针对模型和LoRA的训练,楼主的经验也不多,可以请教其他坛友或寻找专门教程。
如果大家有什么其他好用的furry模型, 非常欢迎推荐给楼主!这里也呼吁其他AI绘图的发布者发帖时尽量标明所使用的模型,方便其他感兴趣的坛友进行尝试~
看了这么多文字,休息一下吧~ 在这里可以猛吸元气狼狼,补充一下毛茸茸能量!
三、咒语/关键词
就如同动漫作品中一样,只有熟练且正确地吟唱咒语,才能够召唤出帅气的毛茸茸到你身边,否则可是会面对古神降临的san值危机哦! (楼主体感最近的新模型稳定度已经在逐步提升了,相比早期已经不太容易出现过于离谱的畸形了) (楼主体感最近的新模型稳定度已经在逐步提升了,相比早期已经不太容易出现过于离谱的畸形了)
众所周知,咒语包含了正面与负面关键词。正面关键词通常包含一些通用部分(比如质量控制,风格等),还有针对你想画主题的特定部分(比如人物、动作、场景等)。负面关键词以质量控制居多,一般只需要复制粘贴就可以,除非需要避免特定物体出现在画面中。关于咒语更详细的构成说明,可以参考元素同典里给出的讲解。
当然对于新手来说,完全自己编写咒语可能会让人没有头绪,而且也不一定适合当前模型(不同模型的咒语构成方式可能有很大不同)。这里建议新人都从复制喜欢的成品图咒语开始,最保险的就是去c站模型页面找对应的示例图,通常情况下给出的写法都是比较适合当前模型的。当你缺乏灵感的时候,也可以逛逛楼主之前推荐的discord频道 furry diffusion,里面会有海量大佬发布的毛茸茸足够你进行参考。本贴最后的图也有楼主给出的咒语示例。
如果你遇到喜欢的图却没有标注咒语,可以尝试用咒语解析网站获取图像中的信息,成功的话还可以看到模型的哈希值(Model hash),在c站上可以直接搜索哈希值找到唯一对应的模型(如果有的话)。特别注意如果图像非原图,或经过后期修正的话(比如楼主大部分的图),就无法进行解析了。
想要熟练吟唱咒语,脑海中通常需要一定的积累量。需要熟知每个关键词以及组合后可能对应的出图效果,比如各位画师的风格(古典和现代)以何种方式融合出你想要的画风。这些难免需要大量练习来增加熟练度,不过也有捷径可以走。就拿AI毛茸茸来说,这个链接就给出了(对应yiffymix的)大量艺术家风格、物种/角色,方便各位查阅参考对应咒语(有各种动漫角色比如宝可梦)。
比如这样的角色示意图(链接里提供的),让我看看是谁的兽人老公走丢了~
最后,楼主建议编写咒语的时候一定要在动作与构图上加以限制,这是让你的作品生动起来的关键步骤,如果不规定很可能就是直给的站桩姿势啦(比如上面这张图,不大力调教AI是不会动的 ),这也是很多观众诟病的AI感原因之一。实在想不出来也可以用万能的action pose/dynamic angle大法让AI自己发挥一下。AI绘图虽然下限很高,想要产出高质量的图同样需要在场景设计上下功夫,不断增减场景元素和修改权重也是试验咒语的必要步骤(模型对于不同物体敏感度不同),这里宜多不宜少,毕竟AI经常无法涵盖全部规定的元素。新手可以由简单到复杂,在不断练习之下,相信各位的关键词设计能力也会提高的,一个好的主题能为出图效果增色不少! ),这也是很多观众诟病的AI感原因之一。实在想不出来也可以用万能的action pose/dynamic angle大法让AI自己发挥一下。AI绘图虽然下限很高,想要产出高质量的图同样需要在场景设计上下功夫,不断增减场景元素和修改权重也是试验咒语的必要步骤(模型对于不同物体敏感度不同),这里宜多不宜少,毕竟AI经常无法涵盖全部规定的元素。新手可以由简单到复杂,在不断练习之下,相信各位的关键词设计能力也会提高的,一个好的主题能为出图效果增色不少!
四、出图
在准备好咒语之后就可以进入批量出图阶段啦,在这里你可以体会到抽卡的快感(有惊喜也有惊吓 ),可不要沉迷哦!在这里楼主会简单介绍一下常用的配置参数,并给出一个常见区间,目的是让新手在不知道如何调节的时候也能有一个还算合适的选择,当各位熟悉起来之后就可以按照自己的喜好自由调节啦! ),可不要沉迷哦!在这里楼主会简单介绍一下常用的配置参数,并给出一个常见区间,目的是让新手在不知道如何调节的时候也能有一个还算合适的选择,当各位熟悉起来之后就可以按照自己的喜好自由调节啦!
stable diffusion webui默认界面示意图:
1. 分辨率/图像尺寸:也就是图像的宽度和高度啦,非常关键的参数,AI绘图在分辨率不足的区域很容易出现错误(例如常见的眼部模糊)。虽说高分辨率是好的,但也不建议在批量跑图时拉的太高,除了速度问题外还会造成元素溢出(比如AI觉得你的咒语不够填满画布,自作主张复制多个人物出来)。楼主建议的长宽范围在512-768左右(XL模型1024左右),画幅比例可以根据自己的要求决定。也可以选上高清修复功能(重绘幅度0.6-0.8),能很好地弥补初始图细节不足的问题,但如果是和楼主一样有后续细化步骤,这里也不用分辨率太高(主要是为速度考虑)。
2. 采样方法和迭代步数:采样器的种类有很多,楼主推荐的是Euler a 和DPM++ 2M Karras,主要是这两种都不太吃步数,很少迭代次数就能达到不错效果。虽说理论上迭代步数增加会使画面更精致,但除了减慢速度也会造成过拟合问题。如果使用这两种采样器,批量跑图时步数大约在20-40左右就足够了,后续细化阶段可以拉到40-60。(通常DPM++ 2M Karras绘制的场景更加细致一点,但注意旧版Indigo模型请避免使用该采样器,容易产生明显的过拟合噪点。)
3.总批次和每批数量:就是影响一次跑图出多少张啦,这里非常建议显存不够的把每批数量调成最小,总批次可以拉高,这样可以有效避免溢出现象(CUDA Out Of Memory警告!)。具体数量看你的要求,比如可以把批次拉满,让AI慢慢跑,期间不影响你进行其他工作(可以看一会儿色图放松心情)。
4.提示词引导系数(CFG):就是控制AI有多符合你的咒语描述啦,提高CFG就相当于把所有关键词都提高了权重。CFG的设置一般与模型有关,楼主推荐批量跑初始图的时候可以选7左右, 给AI一定自由发挥的空间;细化阶段可以酌情增加到10,追求更准确的绘制。
基本上重要的参数就是这些了,除此之外,本地部署的sd还可以安装大量功能各异的插件,webui里也方便地支持输入github链接自动配置。由于本期是入门教程,各种进阶功能就留给大家自己探索啦!
在配置好咒语和以上参数后,就可以开始愉快的抽卡之旅啦,这里一定要有耐心,符合自己心意的图经常可遇不可求,不过准确的咒语描述可以让出图效率大大增加。如果是用较低分辨率批量跑图(建议),不用过于注意各种瑕疵,这些都是在细化与修复阶段可以解决的,可以更多地把注意力放在场景和构图上。具体如何挑选就是按照自己的审美和喜好啦~ 虽说AI绘图不需要画技,但对于审美能力的要求是必不可少的,在这里希望各位与楼主共勉,不断提高自己!
五、细化与修复
现阶段AI出图的稳定度还无法达到十全十美的境界,所以后期处理也是非常关键的步骤,想进一步提高出图质量可不要偷懒哦~
1. 细化
由于AI绘制的细节精度直接与分辨率相关,所谓细化阶段就是提高初始图分辨率的过程,这一操作后往往图片质量会有明显提升。(毕竟跑高分辨率是很费时间的,只对少数满意的图进行就会快捷很多了。)细化阶段用到的就是图生图功能啦,除了拉高分辨率之外,也可以针对性地对当前图的咒语进行修改,从而达到更精准的效果。主要也包含两种方式:
全图重绘:(是楼主比较爱用的方式 ,通常拉到1536*1536左右。)优势是整张图的衔接十分自然,基本不会有特别突兀的地方,缺点是可能无法精确到你想修改的点,显存低使用起来会受到限制。注意重绘幅度不要太高(小于0.5),否则会得到基本不相关的图。 ,通常拉到1536*1536左右。)优势是整张图的衔接十分自然,基本不会有特别突兀的地方,缺点是可能无法精确到你想修改的点,显存低使用起来会受到限制。注意重绘幅度不要太高(小于0.5),否则会得到基本不相关的图。
局部重绘:只针对关键处(比如面部)或不满意的区域进行重绘,可以自己手涂蒙版区域。使用时要注意重绘部分与周边区域的衔接,尽量不要过于突兀。至于蒙版下选择原图/填充和重绘幅度就要看具体要求,是要做完全重画(比如修正畸形的肢体或大幅度差分),还是仅作修正(比如增加汗液、衣服和小幅度差分)。比较小的修改就不用专门重绘了,看下一节的介绍自己手动改图经常会更方便。
建议上面两种方法重绘的时候可以每次多跑几张,方便对比选出效果好的。
2. 修复
依靠AI重绘终归还是碰运气的操作,很多时候自己手动修改会更加直接准确。如果没有专业工具可以用win系统自带的画图3D进行编辑(也是楼主最常用的方式),当然如果有精通手绘或PS等方式的大佬就可以不用参考啦,效果只会更好!
首先是可以进行移花接木操作,利用自动抠图(比如画图3D里的神奇选择)把其他图里满意的部分覆盖到当前图中。常见的使用场景是一次性得到的多张重绘图中,发现没办法同时把所有部位都画好,可以把每张图的优势集中起来。还可以利用不同模型进行重绘后组合(比如有的擅长场景,有的擅长人物),甚至把完全不同的图中的元素搬过来,可以尽情发挥想象力~ 要注意的是修改部分与原图的衔接,可以手动涂抹至自然,也可以交给AI小幅度重绘。
其次是直接上手自己画,以画图3D为例,可以先拿水彩笔笔刷范围涂抹,再拿记号笔勾线和进行像素级处理。具体该怎么画就不是楼主能够教学的了,不过完全没有绘画基础也不用担心(楼主也没有),只需大胆勾勒出轮廓,然后交给AI重绘就可以帮你补齐细节和衔接部分。(多加练习会更熟练,楼主现在感觉自己手画起来已经比较得心应手了,甚至经常不用AI重绘帮忙。)
上述细化与修复步骤可以交替进行,并重复多次,具体要看个人满意的标准了,完成后就可以获得完全体的AI毛茸茸啦!
六、示例主题
辛苦各位看完这么长的教程啦,来几张毛茸茸图放松一下吧!
本贴使用的均是Indigo Furry mix 的anime模型(v25)。由于本期教程的特殊性,示例主题的图都附带了咒语(正面关键词),方便各位参考。因为是正经教程,这次都是健全向的图,发生的色色故事请自己脑补或等待楼主后续作品(也可能没有后续)。楼主尽量尝试了多个物种、体型、职业等,以求覆盖面尽量广一点。
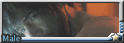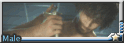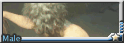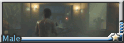
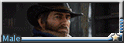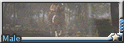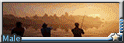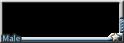
本期的主题为暗巷。在城市不为人知的阴暗角落里,身份各异的兽人们又会摩擦出怎样的故事呢?
upload on e621,(Masterpieces), furry, male, solo, detailed eyes, kemono, by hioshiru and kenket and ((dimwitdog)), Michael & Inessa Garmash, (Pino Daeni, yupa, greg rutkowski), ((detailed fluffy fur)), detailed realistic painting, cinematic, detailed background, perfect light and shade, dynamic angle,
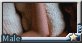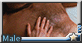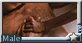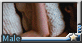
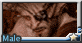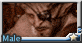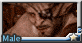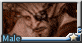
(wolf male), (in dark night modern city), (close shot, close up), cop, technique uniform , (cold face:1.2),(serious face:1.3), (looking at viewer), (in dark narrow alley), police,special troops, tall and strong,muscular, messy rough road, raining night, wet body, (kneel down on one knee ),(blood stain on the ground), (from side), (hand toching the ground:1.2)
upload on e621,(Masterpieces), dragon, male, solo, detailed eyes, kemono, by hioshiru and kenket and ((dimwitdog)), Michael & Inessa Garmash, (Pino Daeni, yupa, greg rutkowski),detailed realistic painting, cinematic, detailed background, perfect light and shade, dynamic angle,
(dragon male), (in dark night modern city), (close shot, close up), open coat , (cold face:1.2),(smirk:1.3), (looking down:1.2), (in dark narrow alley),theft, tall and strong,muscular, (lean against the wall:1.2), raining night, wet body, wearing hoddie, (from side), dark environment, detailed scales, thick tail, (looking at viewer:1.5)
upload on e621,(Masterpieces), furry, male, (solo), detailed eyes, kemono, by hioshiru and kenket and ((dimwitdog)), Michael & Inessa Garmash, (Pino Daeni, yupa, greg rutkowski), ((detailed fluffy fur)), detailed realistic painting, cinematic, detailed background, perfect shade, dynamic angle,
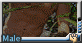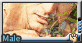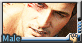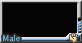
(brown bear male), (in dark night modern city), close shot, close up ,(dustman), tight dustman clothes, (naked overalls:1.2), (dull face:1.2),(small eyes,squint), (looking at viewer), (in dark narrow alley), tall and strong,overweight, holding mopstick and cleaning the ground, messy rough road, (dark raining night), wet body, (from side), cool tone, lightless, from top, looking down,(lean against the wall:1.2),(headband)
upload on e621,(Masterpieces), furry, male, (solo), detailed eyes, kemono, by hioshiru and kenket and ((dimwitdog)), Michael & Inessa Garmash, (Pino Daeni, yupa, greg rutkowski), ((detailed fluffy fur)), detailed realistic painting, cinematic, detailed background, perfect shade, dynamic angle,
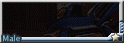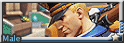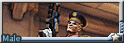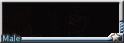
( spotted hyena male), small round hyena ears, (dark brown ears), (dark brown mouth and dark brown nose:1.4), (dark brown muzzle:1.3), (dark brown hands), in dark night modern city, (gangster:1.2),bad guy, (sanpaku), (sleepy eyes:1.2),(disdainful eyes:1.4), (looking away ), close shot, close up ,(cullion face:1.2), (in dark narrow alley), tall and slim body, sitting on a hugh trash bin, (cross legs), messy rough road, (dark raining night), wet body, cool tone, lightless, (colorful fashion punk clothes:1.3),graffiti, flash mobs,tokyo tribe
upload on e621,(Masterpieces), furry, male, (solo), detailed eyes, kemono, by hioshiru and kenket and ((dimwitdog)), Michael & Inessa Garmash, (Pino Daeni, yupa, greg rutkowski), ((detailed fluffy fur)), detailed realistic painting, cinematic, detailed background, perfect shade, dynamic angle,
(white tiger male), in dark night modern city, (bodyguard:1.2), (mourn:1.2),(sorrow eyes:1.4), (looking up:1.4), medium shot,full body, hands in the pocket,(sad face:1.4), (tear and rain on face), (in dark narrow alley), tall and strong body, (huge muscular),huge body, broad shoulder, umbrella on the ground, messy rough road, (dark raining night), wet body, cool tone, lightless, (bussiness suit and shirt),(top view:1.4), fisheye lens, dark blue light
虽然这次没有色色内容,想看高清原图的还是可以去推特自取(https://twitter.com/silencedonkey2)。其实是觉得比上传网盘更快,偷懒了。
小驴的AI毛茸茸教程就到这里啦,有什么问题可以评论区反馈。还等什么快来领取自己的毛茸茸吧!楼主很期待看到各位的作品,暂时用不到的话也可以先收藏一下以备不时之需!
这次总结AI毛茸茸经验楼主花费了很多精力,也算是倾囊相授啦,看的满意或对你有帮助的话还请给个评分追随,求求啦!
本期的投票就调查一下各位对于尝试AI绘画的意愿吧,看看各位属于哪一种情况~
|


 [复制链接]
|关注本帖
[复制链接]
|关注本帖



 GameMale
GameMale
 金币
金币 血液
血液 旅程
旅程 追随
追随 知识
知识 咒术
咒术 堕落
堕落 灵魂
灵魂 主题
主题 回帖
回帖 日志
日志 记录
记录 好友
好友 积分
积分










 提升泵
提升泵 亮色刷
亮色刷 小时顶
小时顶











































































































![苏格兰圆脸胖鸡[Pro Max]](https://img.gamemale.com/album/202412/23/095436g9jeewz4hahg42pp.gif)