|
|
这是之前做汉化的时候写的一个脚本,效果是统计一个文件夹内的所有excel表格/word文档/txt文件
内中/英/日文的字符数量(只有这三种的原因是因为我只会汉这三种),诞生的原因是我想知道自己汉了多少工程量
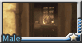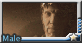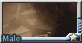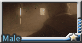
以下是效果图
可能有BUG,因为我压根就没用过多少次。
(pyhthon脚本应该不需要结印了吧)
- import os
- import re
- from docx import Document
- from openpyxl import load_workbook
- # 统计中文、英文、日文字符的函数
- def count_characters(text):
- # 去掉不可见字符,例如换行符、空格等
- text = re.sub(r'\s', '', text) # 移除所有空白字符,包括空格、换行符、制表符等
- # 改进的正则表达式,只匹配平假名和片假名
- chinese_count = len(re.findall(r'[\u4e00-\u9fff]', text))
- english_count = len(re.findall(r'[a-zA-Z]', text))
- japanese_count = len(re.findall(r'[\u3040-\u309f\u30a0-\u30ff]', text)) # 平假名和片假名
- return chinese_count, english_count, japanese_count
- # 处理 Word 文档
- def process_word(file_path):
- chinese_total = english_total = japanese_total = 0
- try:
- doc = Document(file_path)
- for para in doc.paragraphs:
- chinese, english, japanese = count_characters(para.text)
- chinese_total += chinese
- english_total += english
- japanese_total += japanese
- except Exception as e:
- print(f"Error processing Word file {file_path}: {e}")
- return chinese_total, english_total, japanese_total
- # 处理 Excel 表格
- def process_excel(file_path):
- chinese_total = english_total = japanese_total = 0
- try:
- workbook = load_workbook(file_path, read_only=True)
- for sheet in workbook.worksheets:
- for row in sheet.iter_rows(values_only=True):
- for cell in row:
- if cell is not None:
- chinese, english, japanese = count_characters(str(cell))
- chinese_total += chinese
- english_total += english
- japanese_total += japanese
- except Exception as e:
- print(f"Error processing Excel file {file_path}: {e}")
- return chinese_total, english_total, japanese_total
- # 处理 TXT 文件
- def process_txt(file_path):
- chinese_total = english_total = japanese_total = 0
- try:
- with open(file_path, 'r', encoding='utf-8') as file:
- content = file.read()
- chinese, english, japanese = count_characters(content)
- chinese_total += chinese
- english_total += english
- japanese_total += japanese
- except Exception as e:
- print(f"Error processing TXT file {file_path}: {e}")
- return chinese_total, english_total, japanese_total
- # 遍历文件夹并统计字符数(包括递归子文件夹)
- def process_folder(folder_path):
- total_chinese = total_english = total_japanese = 0
- # 使用 os.walk 递归遍历所有子文件夹及文件
- for root, _, files in os.walk(folder_path):
- for file in files:
- file_path = os.path.join(root, file)
- # 只处理指定类型的文件
- if file.endswith('.docx'):
- print(f"Processing Word file: {file_path}")
- chinese, english, japanese = process_word(file_path)
- total_chinese += chinese
- total_english += english
- total_japanese += japanese
- elif file.endswith('.xlsx'):
- print(f"Processing Excel file: {file_path}")
- chinese, english, japanese = process_excel(file_path)
- total_chinese += chinese
- total_english += english
- total_japanese += japanese
- elif file.endswith('.txt'):
- print(f"Processing TXT file: {file_path}")
- chinese, english, japanese = process_txt(file_path)
- total_chinese += chinese
- total_english += english
- total_japanese += japanese
- # 输出统计结果
- print("\nFinal Character Count:")
- print(f"Total Chinese characters: {total_chinese}")
- print(f"Total English characters: {total_english}")
- print(f"Total Japanese characters: {total_japanese}")
- # 主函数入口
- if __name__ == "__main__":
- folder_path = input("Enter the folder path: ")
- folder_path = folder_path.strip() # 去除输入路径中的多余空格
- if not os.path.exists(folder_path):
- print(f"Error: The folder path '{folder_path}' does not exist.")
- else:
- process_folder(folder_path)
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
评分
-
查看全部评分
|


 GameMale
GameMale
 金币
金币 血液
血液 旅程
旅程 追随
追随 知识
知识 咒术
咒术 堕落
堕落 灵魂
灵魂 主题
主题 回帖
回帖 日志
日志 记录
记录 好友
好友 积分
积分










 楼主
楼主 提升卡
提升卡 变色卡
变色卡 千斤顶
千斤顶




































































 蛮好用的样子 真是挖到宝了
蛮好用的样子 真是挖到宝了