現在似乎各家語言模型 ( Chatgpt, Grok, ) 具備圖片生成都是標準功能了, 只是背後可能用的是不同的生成引擎.
之前付費試過 Chatgpt 生圖過, 雖然跟 Bing 一樣用的都是 Dalle3, 但是敏感審查的程度簡直比Bing還誇張, 用過了十分失望 
另外也一直想嘗試一下 Google 的 Imagen3 生圖引擎, 但是其網站居然沒有開放給美國以外的區域使用
所幸聽聞Google的語言模型 Gemini 已經開放生圖功能給一般人使用了, 而且第一個月試用免費, 就來試試看來著
結果怎麼說呢, 審查一樣相當嚴格, 我只要白絲大包, 被拒絕率也相當高,
同時它生成的風格也很"寫實", 褲襪下的包尺寸都相當 小 真實, 所以很難有很真的大包.
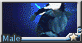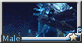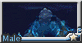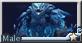
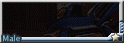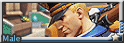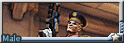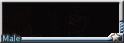
但它生成的男性芭蕾服裝應該是我試到目前所有引擎中款式最還原的, 這點到是個亮點 而且每張圖的分辨律都高達 2048 x 2048 而且每張圖的分辨律都高達 2048 x 2048
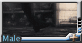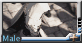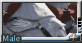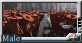
就隨意給大家分享一下了芭蕾之美了 (來自某個看芭蕾從來只看服裝跟大包而不關注表演的變態 ) )
迷你但很寫實的包:
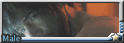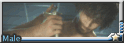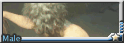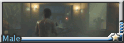
為了嘗試更多角色形象可能性, 意外的跑出了胖熊舞男
穿襪中
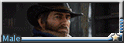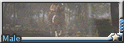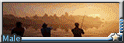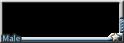
我很喜歡的一張, 伐木工風格刺青硬漢 in 芭蕾王子裝
芭蕾抱抱系列:
摔角壯漢 in 芭蕾王子裝系列:
也有試過比較老電影濾鏡的風格, 總覺的50年代審美的鬍子男都比現在還可口啊 x
|

 [复制链接]
|关注本帖
[复制链接]
|关注本帖

 GameMale
GameMale
 金币
金币 血液
血液 旅程
旅程 追随
追随 知识
知识 咒术
咒术 堕落
堕落 灵魂
灵魂 主题
主题 回帖
回帖 日志
日志 记录
记录 好友
好友 积分
积分






 楼主
楼主 提升泵
提升泵 亮色刷
亮色刷 小时顶
小时顶



















![苏格兰圆脸胖鸡[Pro Max]](https://img.gamemale.com/album/202412/23/095436g9jeewz4hahg42pp.gif)